



Maximizing QA Impact: Tools, Scaling, Metrics, and the Role of AI
This blog post is adapted from Tina Wu’s talk at TrustCon 2025, titled “Maximizing QA Impact: Tools, Tactics, and Tradeoffs”
When I first started building QA tools, I assumed the job was only about increasing reviewer accuracy so that the money that platforms pay for moderators is worth it.
I was very wrong.
What teams really need is to feel confident that the right decisions are being made, especially when they impact users or the platform. And I learned that QA is a constant battle between getting highly accurate decisions, getting breadth of coverage across policies and content types, and never having enough people.
Here’s what I’ve learned from building QA tools, watching how they’re used in the real world, and understanding the messy, high-stakes tradeoffs teams face every day.
Matching tools to the tradeoffs you're making
If you’ve ever run a trust and safety QA program from inside a tangled web of spreadsheets, filters, and color-coded pivot tables, I feel you. Quality assurance in trust and safety is one of those behind-the-scenes engines that quietly shapes the entire user experience (and brand reputation) of digital platforms. Effective QA is a force multiplier. But the reality is, most QA programs are these Frankenstein’ed, manual workflows that are stuck navigating impossible tradeoffs between accuracy, coverage, and resourcing.
Instead of viewing QA as a one-size-fits-all compliance function, it's time to start thinking of it as a system:
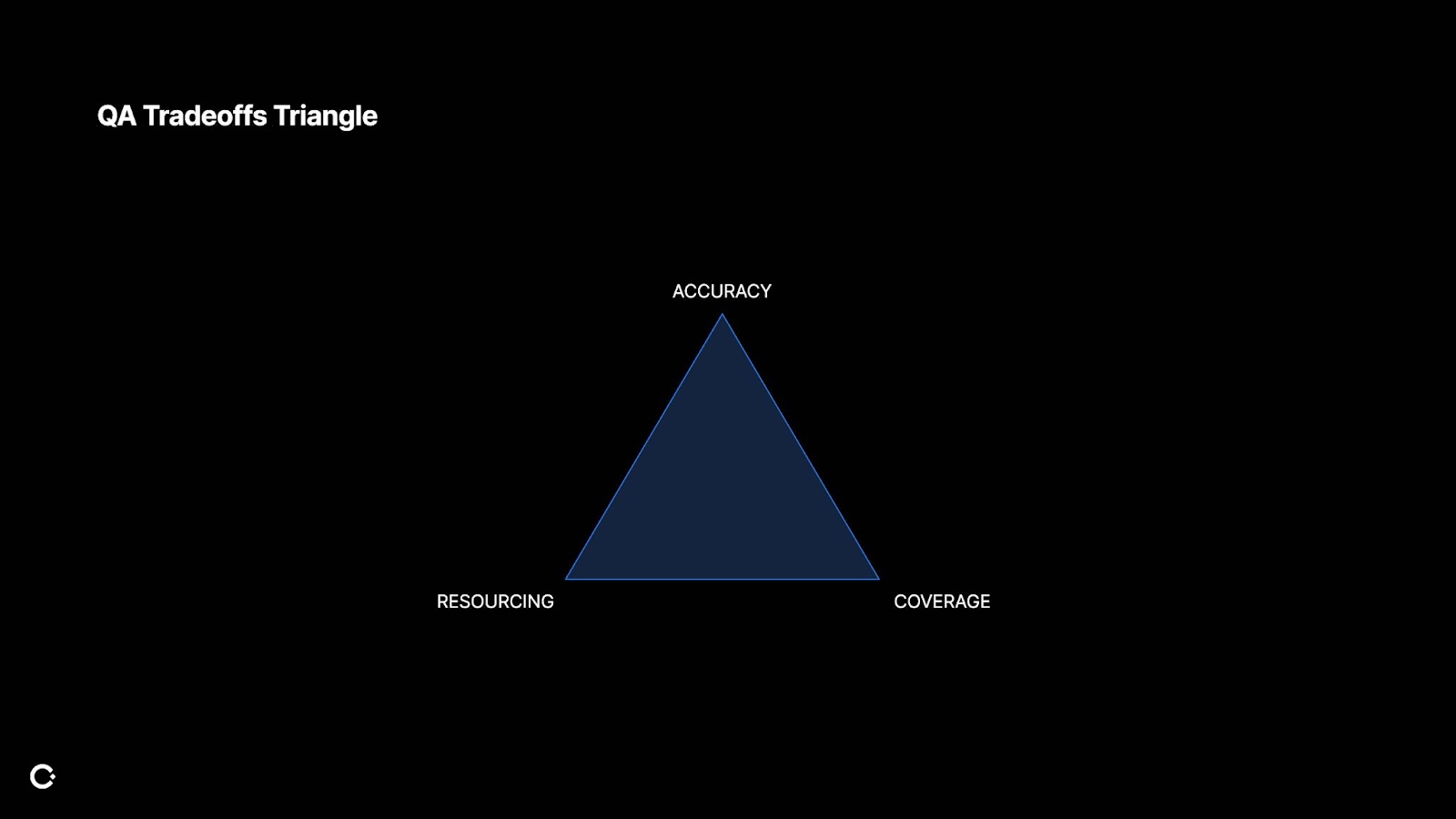
This is what I like to call the QA Tradeoffs Triangle. You can rarely optimize for all three at once. QA is often about choosing which tradeoff to make depending on your risk and maturity.
Accuracy: You want to have deep reviews and you want to make the right decisions.
Coverage: You want breadth across all your products, policies, verticals, and enforcement actions
Resourcing: You want more people and more budget and more time.
It’s incredibly hard to get all three, and maybe for a short while you do, but then your product team is probably coming to you about to launch a new product or feature, or someone’s about to pass a policy for which you now need to be compliant.
Here’s how you can navigate these tradeoffs through tools, strategy, and automation:
QA tools overview: not a one-size-fits-all solution
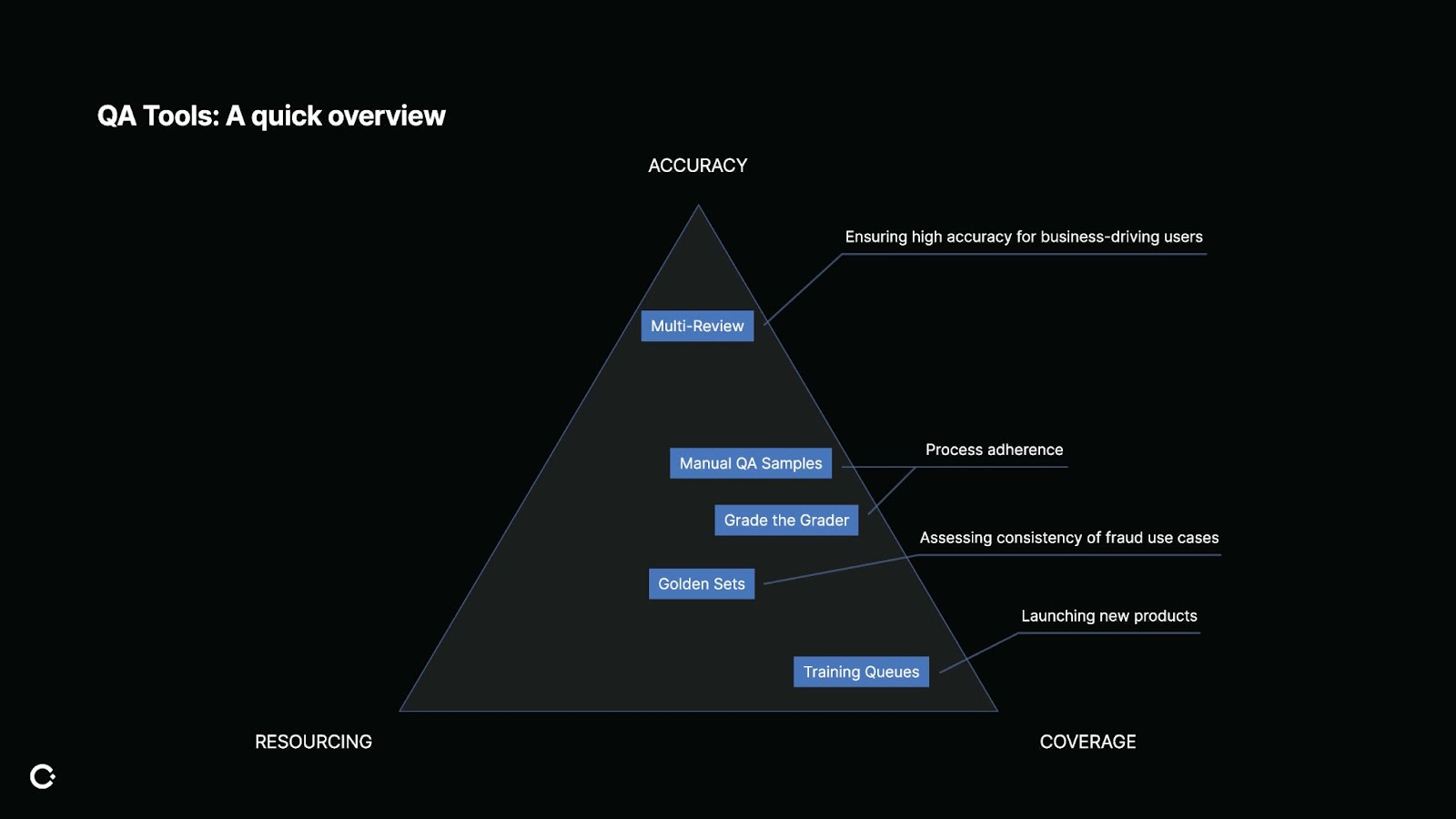
First, a quick overview of the different types of QA tools, because they can serve very different needs:
Training Queues: These are great for coverage when launching new products or onboarding new reviewers. Think of them as sandbox environments filled with dummy content. Want to see how your team would enforce a brand-new chat feature? Load it up in a training queue and test it before it goes live. Training queues help you achieve coverage across new areas and reduce operational risk.
Multi-Review: Here, accuracy is critical. Multiple reviewers must independently agree before a decision is finalized. This is perfect when you’re dealing with high-value users or business-critical actions. For example, if you're a marketplace, your platform has high value sellers that drive the majority of your platform's revenue. For these sellers, you want your decisions to be highly accurate and you're willing to take the tradeoff of resourcing to spend more reviewer time for those decisions. It's expensive and doesn't expand your coverage, but it's worth it when the stakes are high.
“Multi-review has increased our high-value [users’] trust and we’ve increased seller NPS (net promoter score) as a result.” - QA Manager
Golden Sets: A fan favorite for assessing both accuracy and edge-case coverage. These are test items with known answers, silently injected into queues to see how reviewers perform. Maybe you came across a fraud chat message, and you noticed a new pattern. You can then put that fraud example in a golden set to get signals on how all reviewers would have enforced that. In this case, golden sets support accuracy but also improve coverage of edge cases that might otherwise be missed.
Manual QA & Grade the Grader: Both of these involve manual reviews of a sampled set, where regular QA samples real decisions and grade the grader QA samples QA decisions. (And yes, manual reviews still matter!) Both of these methods provide accuracy by manually re-reviewing decisions and coverage, but only if you sample smartly.
Let’s say you're looking at process adherence, for example, and you want to see if reviewers are correctly escalating content, and to the right destinations. Manual QA can be used to ensure reviews follow expected operational guidance. There's a lot of flexibility with manual QA but they're human-heavy, so come at a resourcing cost. Think of them as high-effort, high-impact tools.
None of these tools are perfect, but each fits a different combination of goals and constraints. It's up to you to use them intentionally for the risks and tradeoffs you're willing to make.
Scaling QA strategically, not uniformly
Not all scaling operations are equal. Scaling your QA program may look different depending on the optimizations you want to make.
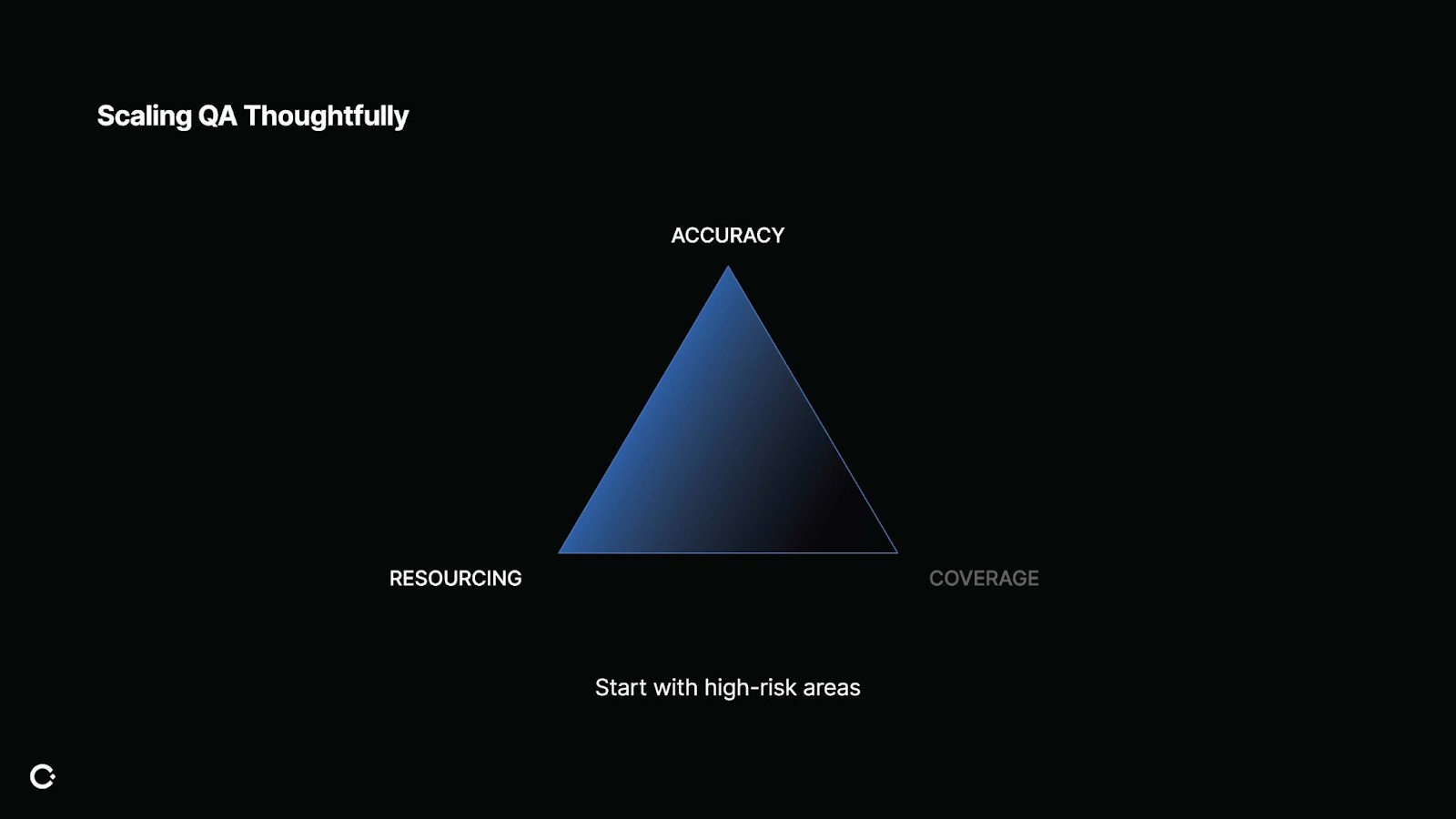
Start by focusing your QA efforts on high-risk areas. These might be policies with legal or reputational stakes or decisions involving high-value users. In these cases, the cost of a bad decision, whether it's platform abuse that goes unflagged or an unfair ban of a top creator, far outweighs the cost of conducting an extra QA review. You don’t need perfect coverage; you just need to be right about what matters most.
Next piece of advice: Don’t reinvent the wheel.
Whether it's scorecard templates, sampling logic, or even whole QA workflows, someone else probably has done it. Reusing what has worked saves on resourcing and can unlock unexpected coverage. One team I worked with needed better coverage for low-volume policies, and we solved that by borrowing a sampling technique from another team trying to get even reviewer distribution. With a bit of tweaking, the same logic served two very different needs.
So, reuse what works for other people, and if it isn't exactly 100% what you're looking for, there's likely some overlap that you can tweak to fit your use cases.
It’s also important to be thoughtful about how you scale. This one's a mindset shift. Too often, QA is treated like a pure score card and grading system. But QA should be a strategic input: It tells you what's broken, not just who made a mistake.
If process adherence is low, maybe that’s not a training problem. Instead, it might mean that there's unnecessary friction in the review tool. They might be skipping steps because the tooling made it painful. In this case, QA data is essential to prioritize tooling improvements.
By using QA for prioritization and driving impactful changes, this improves accuracy in the long run, because you're not just correcting mistakes, you're preventing them.
And finally, leverage appeals. Users are giving you QA signals for free, especially in edge cases and ambiguous policy areas. In terms of resourcing, the passage of the Digital Services Act (DSA) means appeals are now required. While reviewing appeals still requires human time, they come in user-initiated so you're not spending additional time collecting samples or finding niche content.
For example, it might be that certain reviewers are interpreting and therefore enforcing policies differently. Appeals help with accuracy by surfacing these ambiguities.
Appeals come from every corner of your platform, so they can help you detect inconsistencies, identify reviewer confusion, and even catch policy gaps. They come with their own noise, of course, but in aggregate, they offer crucial directional data. Appeals help balance all three corners of the triangle: accuracy, coverage, and resourcing.
Metrics: What gets measured, gets improved
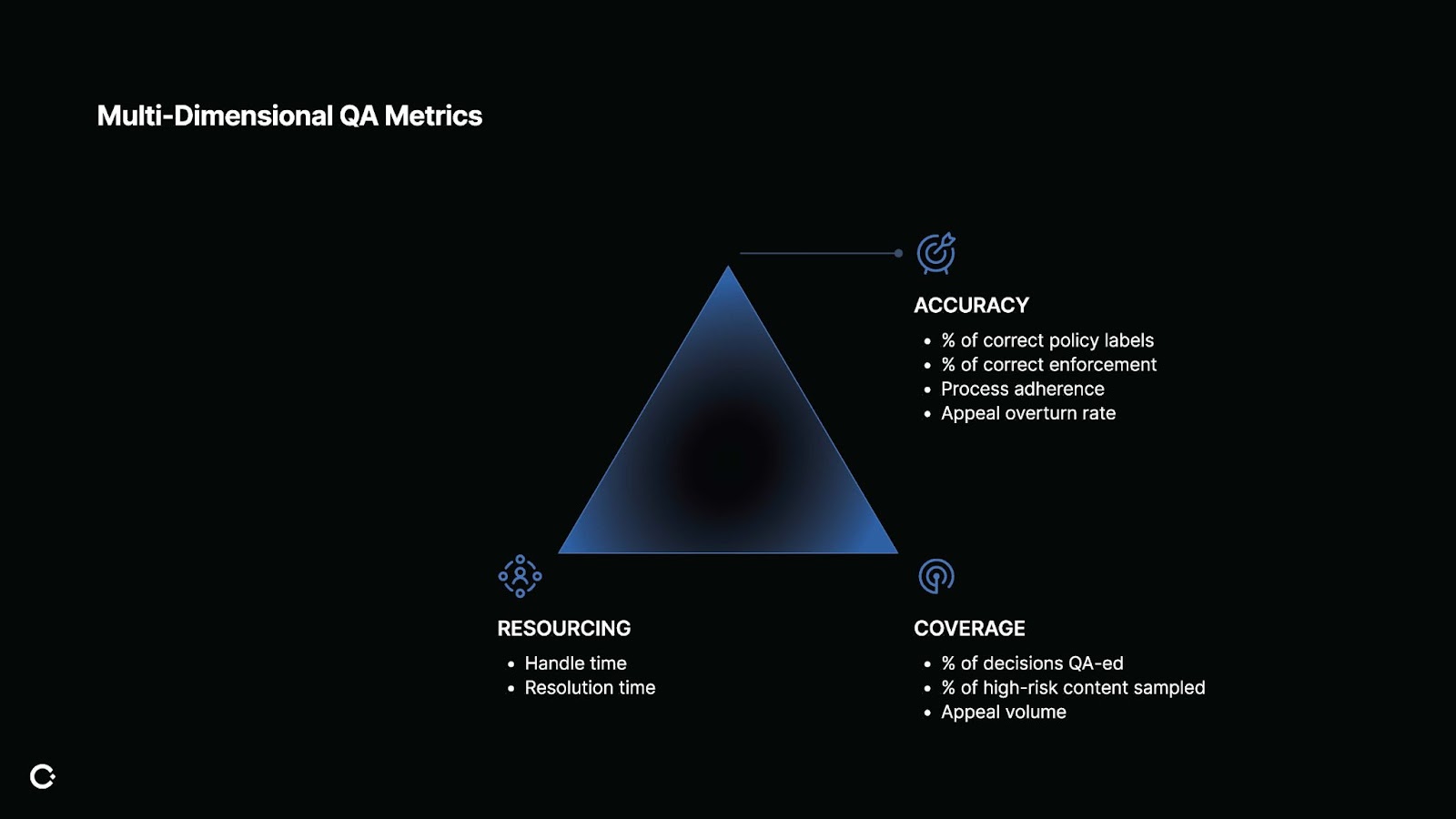
Without the right metrics, even the most sophisticated tools and strategies can’t tell you whether your program is driving the outcomes you care about. Worse, you risk optimizing for the wrong things, like perfect accuracy in areas that don’t affect users, or exhaustive coverage of low-impact content. The best QA programs measure across three dimensions: accuracy, coverage, and resourcing.
Accuracy: At its core, accuracy is about evaluating: did we make the right decision, for the right reason, in the right way?
The key metrics to track are:
- Percentage of correct policy labels: Did the reviewer choose the right policy
- Percentage of correct enforcement: Was the action - like a takedown or a warning - correct?
- Process adherence: Did the reviewer follow the right steps, like escalating or reviewing additional context when required?
These metrics help you understand not just what the reviewer decided but how they got there.
And perhaps most importantly, appeal overturn rates provide a backdoor signal into policy clarity and reviewer confusion.
Coverage: Coverage is a tradeoff I see QA teams struggle with all the time, because there is never enough people and everyone needs to ruthlessly prioritize where they QA.
Unlike accuracy, coverage metrics should answer a different question: are you reviewing enough of the right decisions? Measuring the percentage of total decisions QA-ed gives you a baseline, but breaking this down by policy area or content type helps ensure you're not over-sampling low-risk issues like spam while under-sampling fraud or harassment.
Appeal volume is also a key coverage signal. If one policy accounts for a disproportionate share of appeals but only a tiny fraction of QA effort, it's time to rebalance your sampling strategy.
Resourcing: Resourcing isn't just about the size of your QA team. It's about how much time and effort QA takes from your entire operation, including in production.
For handle time, this is the time it takes to complete a review, in QA or in production. Longer handle times often means more complex processes, detailed scorecards, or unclear policies. That can slow down review velocity, especially if you're doing manual QA with multiple layers.
For resolution time, this is the time it takes for a job to get a final decision. Take multi-review for example: The decision now needs 2 to 3 reviews to align before action is taken, so your production decision itself is delayed, and you're spending 1-2 extra reviewer time.
“Insights from QA metrics has helped us identify process and policy gaps, improve accuracy, and confidently shift more work to our vendors - freeing up time for our internal team to focus on complex cases.” - Trust & Safety Product Manager, Patreon
AI and automation: not a replacement, but an enhancement
Scaling QA isn’t just about reviewing more. It’s about reviewing smarter: focusing human attention where it’s most needed, and focusing your expertise where it’s most impactful.
And if you're feeling skeptical about AI, that's OK. But what I want to show you is how teams like yours can start to use it in ways that don't replace your expertise, but instead, amplifies it.
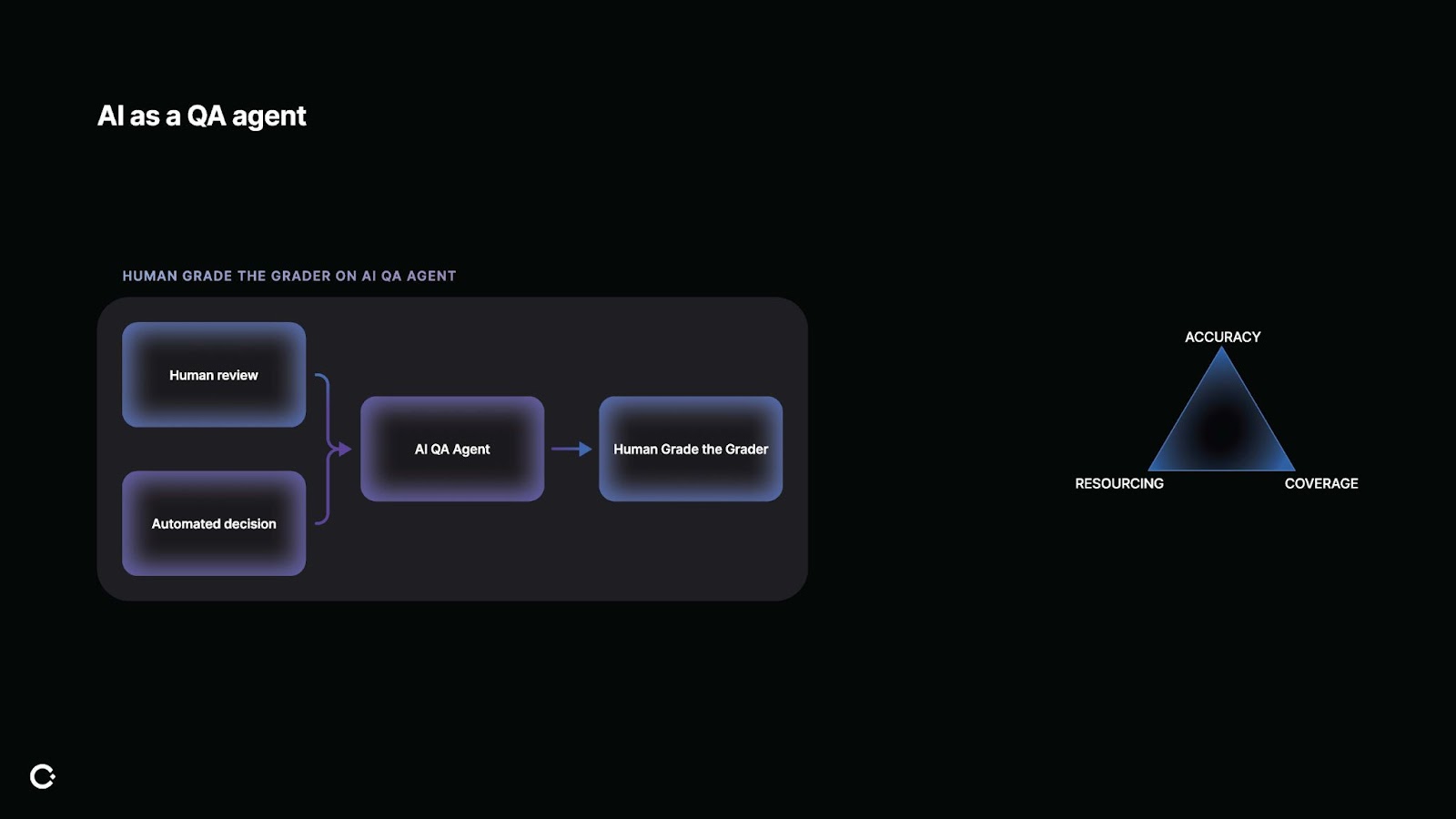
This is where we get to challenge the triangle. Normally, if you want high accuracy and high coverage, it costs a lot of resourcing. But with AI, you can start to shift that.
Using AI to do first-pass QA is a great thing to start, especially if you're not fully comfortable or don't trust AI yet to make production decisions.
Using AI as a QA agent gives you the breadth of coverage and also allows you to build confidence in the model. Then, your human QA agents can grade the AI. This practice maintains human oversight, but with more scale.
AI as of right now is best for high volume and low complexity moderation, such as individual chat messages. When you feel confident enough, you can roll that QA agent into production and move your humans to more complex reviews. You may also find that the agent is good at some areas, like detecting phishing, but not others like complex scams. With this system, you can intentionally decide what to automate and when.
This approach of AI as a complement to your workforce, not a replacement, gives you more coverage and more consistency without costing the proportionate amount of humans.
Leveraging AI for anomaly detection
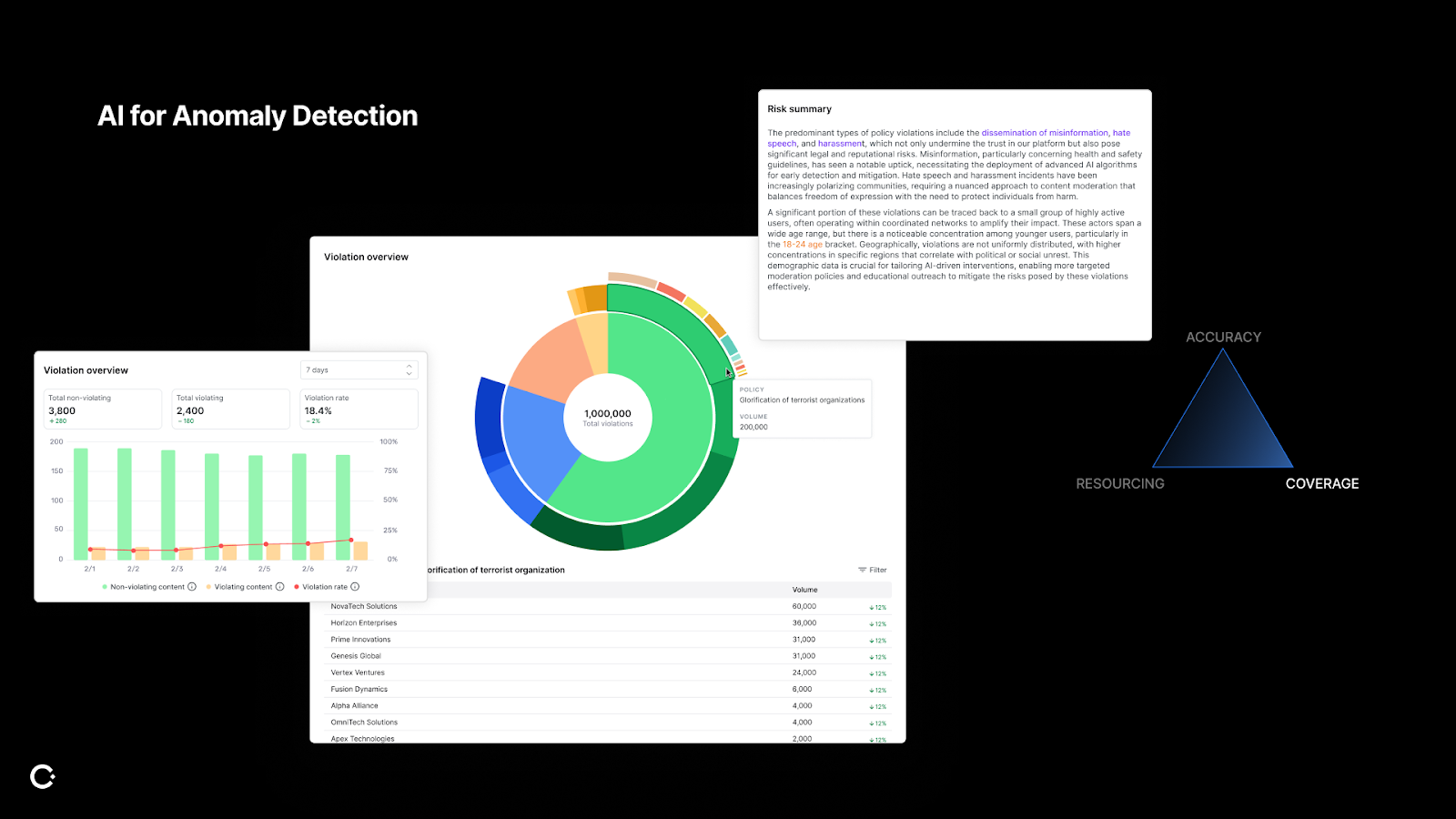
And even if you're not ready to trust AI with decisions, you can use it to supercharge your insight. There’s a lot of expertise from knowing the right questions to ask to surface the right metrics. Instead of spending time writing formulas and pivoting Google Sheets, AI can be used to help answer your questions. You can ask AI to show you what's changing and why.
It can also be used to surface new trends. For example, maybe one month you’ve noticed the phishing violations have gone up. Instead of QA-ing each phishing violation, AI can easily provide a summary insight for you to make policy adjustments or provide additional reviewer training. It can surface emerging content patterns that individual reviewers wouldn’t have caught on as quickly.
So this isn't about automation replacing people. It's about freeing up your time to focus on nuance and strategy that require your expertise.
QA in closing

If there's one thing to take away, it's that QA is about making smart tradeoffs on purpose.
You don't need to QA everything, or optimize every metric. You need to QA the things that matter most, with the tools and resourcing you've got, and evolve from there.
Whether you're launching new features, scaling to support a larger reviewer team, or navigating regulatory changes like the Digital Services Act, QA is a powerful mechanism for aligning your decisions with your strategic goals. Use it to drive better policy enforcement, and ultimately, a safer and more trustworthy platform.